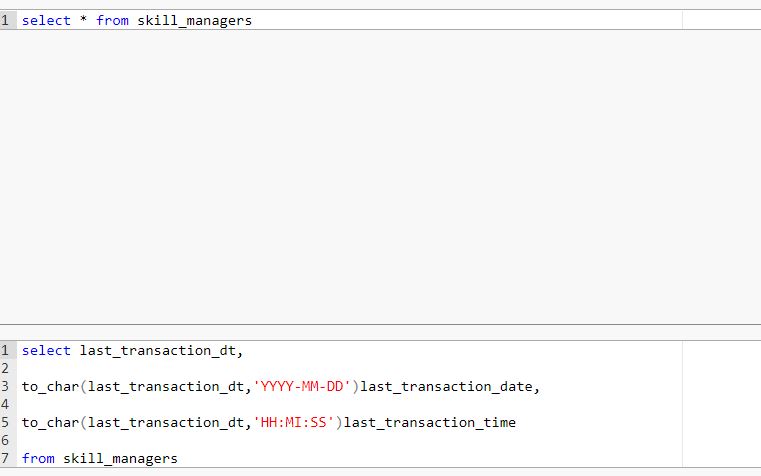

select first_name, last_name,
date_part('year',birth_date) year_of_born from skill_managers
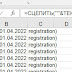
where date_part('hour',last_transaction_dt)>=22select first_name, last_name,
date_part('year',birth_date) year_of_born from skill_managers
where date_part('hour',last_transaction_dt)>=22





import pandas as pd
from scipy.stats import t import matplotlib.pyplot as plt array1 = [84.7, 105.0, 98.9, 97.9, 108.7, 81.3, 99.4, 89.4, 93.0, 119.3, 99.2, 99.4, 97.1, 112.4, 99.8, 94.7, 114.0, 95.1, 115.5, 111.5] array2 = [57.2, 68.6, 104.4, 95.1, 89.9, 70.8, 83.5, 60.1, 75.7, 102.0, 69.0, 79.6, 68.9, 98.6, 76.0, 74.8, 56.0, 55.6, 69.4, 59.5] # считаем количество элементов, среднее, стандартное отклонение и стандартную ошибку df = pd.DataFrame({'Выборка1':array1, 'Выборка2':array2}).agg(['mean','std','count','sem']).transpose() df.columns = ['Mx','SD','N','SE'] # рассчитываем 95% интервал отклонения среднего p = 0.95 K = t.ppf((1 + p)/2, df['Mx']-1) df['interval'] = K * df['SE'] #строим графики, boxplot из изначальных данных array1, array2, доверительные интервалы из датафрейма df fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(14, 9)) # график boxplot bplot1 = ax1.boxplot([array1, array2], vert=True, # создаем вертикальные боксы patch_artist=True, # для красоты заполним цветом боксы квантилей labels=['Выборка1', 'Выборка2']) # используется для задания значений выборок в случае с boxplot # график доверительных интервалов bplot2 = ax2.errorbar(x=df.index, y=df['Mx'], yerr=df['interval'],\ color="black", capsize=3, marker="s", markersize=4, mfc="red", mec="black", fmt ='o') # раскрасим boxplot colors = ['pink', 'lightgreen'] for patch, color in zip(bplot1['boxes'], colors): patch.set_facecolor(color) # добавим общие для каждого из графиков данные for ax in [ax1, ax2]: ax.yaxis.grid(True) ax.set_title('Температура плавления ДНК двух типов') ax.set_xlabel('Сравнение двух выборок') ax.set_ylabel('Температура F') plt.show()library(tidyverse)
library(gridExtra) df <- tibble("Выборка1" = c(84.7, 105.0, 98.9, 97.9, 108.7, 81.3, 99.4, 89.4, 93.0, 119.3, 99.2, 99.4, 97.1, 112.4, 99.8, 94.7, 114.0, 95.1, 115.5, 111.5), "Выборка2" = c(57.2, 68.6, 104.4, 95.1, 89.9, 70.8, 83.5, 60.1, 75.7, 102.0, 69.0, 79.6, 68.9, 98.6, 76.0, 74.8, 56.0, 55.6, 69.4, 59.5)) # считаем среднее, стандартное отклонение, к-во элементов и стандартную ошибку df %>% gather(factor_key = TRUE) %>% group_by(key) %>% summarise(mean = mean(value), sd = sd(value), n = n(), se = sd / sqrt(n)) # график boxplot box_plot <- df %>% gather(factor_key = TRUE) %>% group_by(key) %>% ggplot(aes(x = key, y = value, fill = key)) + geom_boxplot() + stat_summary(fun = mean, geom = "point", shape = 20, size = 3, color = "red", fill = "red") + theme(legend.position = "none") + labs(title = "Температура плавления ДНК двух типов", subtitle = "Boxplot", tag = "Рис. 1", x = "Сравнение двух выборок", y = "Температура F") # график errorbar error_bar <- df %>% gather(factor_key = TRUE) %>% group_by(key) %>% ggplot(aes(x = key, y = value)) + stat_summary(fun="mean", geom="point", color = "red") + stat_summary(fun.data="mean_cl_normal", geom="errorbar", size=1, width=0.2) + labs(title = "Температура плавления ДНК двух типов", subtitle = "График доверительных интервалов", tag = "Рис. 2", x = "Сравнение двух выборок", y = "Температура F") # совмещение графиков grid.arrange(box_plot, error_bar, ncol=2)Товары не пересчитываются на корзине на два товара. Цена стоит за три.
Совершенно хамским тоном клиентская поддержка это отрицает и за заказанные два товара не выдала третий

Чтобы таргетировать рекламу Адвордс только назаданные площадки нужно выполнить следующие действия:
1. Отключить в группе объявлений все другие виды таргетинга. К сожалению таргетинги больше не пересекаются и не накладывают ограничения, а плюсуются. Например выбрав аудиторию шопоголики и площадки, Гугл будет показывать рекламу и на сайтах где присутствует данная аудитория и на площадках заданных вами.
В итоге вы увидите список совсем других сайтов в местах размещения.
2. Проверить что у вас не задно автоматичесаое расширение таргетинга.
Для этого нажмите на группу объявлений, далее "изменить таргетинг группы объявлений" и в разделе "Расширение таргетинга" передвиньте рычаг на "Выкл". И так в каждой группе.

У нас есть таблица invoice_order_operations

который мы создаем в базе:
create table product (product_id int IDENTITY(1,1),
product varchar(255));
Делается это простым запросом:
insert into product
select DISTINCT (product) from invoice_order_operations
итог:

Задача следующая:
Нужно посчитать среднее время нахождения на каждом статусе между отрезками (с учетом повторяющихся статусов).
Таблица выглядит так

Нужно понять как долго клиент находился на каждом этапе сделки


Теперь разбиваем это на каждую сделку